公開資訊站 簽證會計師 產業類別 樞紐分析
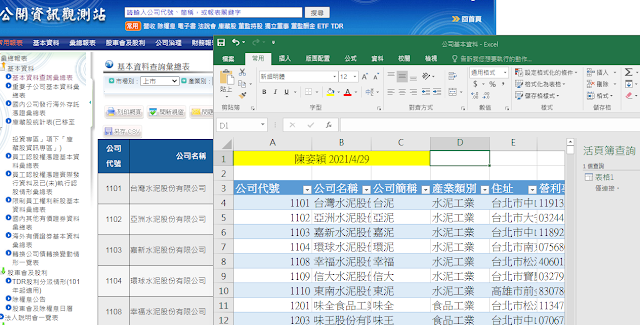
公開資訊站 1101 台灣水泥股份有限公司 台泥 水泥工業 台北市中山北路2段113號 " 1102 亞洲水泥股份有限公司 亞泥 水泥工業 台北市大安區敦化南路2段207號30、31樓 " 1103 嘉新水泥股份有限公司 嘉泥 水泥工業 台北市中山北路2段96號 " 1104 環球水泥股份有限公司 環泥 水泥工業 台北市南京東路二段125號10樓 " 1108 幸福水泥股份有限公司 幸福 水泥工業 台北市松江路237號15樓 " 簽證會計師 產業類別 樞紐分析 美國公開資訊站 美國的公開資訊站edgar只屬於證管會,是國家機構。


